Gemeinsam mit CIMT starteten im Jahr 2019 zwei weitere BMBF-geförderten Nachwuchsgruppen in der sozial-ökologischen Forschung mit einem Fokus auf dem Verständnis und der Gestaltung der Verkehrswende: Experi, mit einem Fokus auf der Rolle von Reallaboren für die Mobilitätswende, und MoveMe mit einem besonderen Augenmerk auf den Besonderheiten für die Verkehrswende im suburbanen Raum.
In den letzten Jahren wurden zahlreiche theoretische und empirische Beiträge erarbeitet, und mittlerweile liegen in allen drei Nachwuchsgruppen zahlreiche Erkenntnisse vor. Im Rahmen eines gemeinsamen zweitägigen Workshops haben sich die drei Nachwuchsgruppen am 25. &. 26. Oktober in Hannover zu einem intensiven Austausch getroffen.
Ziel war die Vorstellung der jeweiligen Erkenntnisse, der Austausch über gemeinsame Herausforderungen, und die Identifikation möglicher Schnittstellen. Unter dem übergeordneten Anliegen der Gestaltung der Verkehrswende wurden dabei eine Reihe von Themen deutlich, zu denen in den Gruppen mit verschiedenen theoretischen Ansätzen und empirischen Methoden neue Perspektiven erarbeitet werden. Dazu gehören die Akzeptanz von Verkehrswendemaßnahmen, die Bedeutung von Partizipation und Konsultationsprozessen sowie die konkreten Optionen für eine Ausgestaltung zukünftiger Mobilität.
Der Workshop soll als Impuls dienen, in Zukunft verschiedene Formate der Zusammenarbeit auszuloten, z.B. in Form von gemeinsamen Veranstaltungen, Publikationen oder Projekten.
In diesem Beitrag auf der 14th International Conference on Recent Advances in Natural Language Processing werden Metriken vorgestellt, um praxisrelevante Anforderungen der Einsetzbarkeit von KI-basierten Werkzeugen zu evaluieren.
Zusammenfassung
Eine Lösung für begrenzte Annotationsbudgets ist aktives Lernen (Active Learning / AL), ein gemeinschaftlicher Prozess von Mensch und Maschine zur strategischen Auswahl einer kleinen, aber informativen Menge von Beispielen. Während aktuelle Maßnahmen AL aus der Perspektive des maschinellen Lernens optimieren, argumentieren wir, dass für eine erfolgreiche Übertragung in die Praxis zusätzliche Kriterien auf die zweite Säule von AL, die menschlichen Annotator*innen und ihre Bedürfnisse, abzielen müssen. Beispielsweise wird der Nutzen von AL-Verfahren im Bereich der Textklassifikation durch gängige Gütemaße wie Accuracy oder F1 bewertet. Solche Maße greifen jedoch bei praxisnahen Datensätzen, die eine erhöhte Anzahl von unausgewogenen Klassen aufweisen, zu kurz, da hier weitere Kriterien wie das schnelle Finden aller Klassen (z.B. Themen) oder die Identifikation seltener Fälle eine Rolle spielen. Wir führen daher vier Maße ein, die die klassenbezogenen Anforderungen widerspiegeln, die Benutzer*innen an die Datenerfassung stellen.
In einem umfassenden Vergleich von Unsicherheits- (Uncertainty), Diversitäts- (Diversity) und hybriden Datenauswahlstrategien auf sechs verschiedenen Datensätzen stellen wir z.B. fest, dass eine starke F1-Leistung nicht unbedingt mit einer vollständigen Klassenabdeckung verbunden ist (d.h. es werden nicht alle Themen gefunden) und dass die verschiedenen Datenauswahlstrategien unterschiedliche Stärken und Schwächen bezüglich der klassenbezogenen Anforderungen aufzeigen. Unsere empirischen Ergebnisse unterstreichen, dass eine ganzheitliche Betrachtung bei der Bewertung von AL-Ansätzen unerlässlich ist, um ihre Nützlichkeit in der Praxis sicherzustellen. Zu diesem Zweck müssen Standardmaße für die Bewertung von maschinellen Textklassifikationsverfahren durch solche ergänzt werden, die die Bedürfnisse der Nutzer besser widerspiegeln.
Wesentliche Ergebnisse
In dieser Publikation werden vier neue klassenbezogene Gütemaße für AL-Ansätze vorgeschlagen, die berücksichtigen, wie gut und schnell seltene oder alle Klassen erkannt werden. Diese Kriterien werden von Standardmaßen (z.B. F1) nicht im Detail berücksichtigt.
Die neuen Maße ermöglichen praxisrelevante Einsichten in die Performanz insbesondere auf Datensätzen mit unterschiedlichen oft vorkommenden Klassen sowie einer großen Spanne an verschiedenen Klassen – Eigenschaften, die in der Praxis (z.B. bei der Themenerkennung in Beteiligungsverfahren) weit verbreitet sind.
Es zeigt sich, dass die Wahl einer geeigneten AL-Strategie nicht nur aufgrund von Standardmaßen getroffen werden sollte. Die besten Ansätze nach dem F1-Maß können z.B. nicht sicherstellen, dass auch alle Klassen gefunden werden, obgleich dies eine essenzielle Anforderung in der automatisierten Auswertung von Beteiligungsbeiträgen ist: kein Thema sollte vernachlässigt werden, keine Stimme untergehen. Die von uns entwickelten Maße können die Auswahl zusätzlich informieren und so praxisorientierte Lösungen liefern.
Publikation
Romberg, J. (2023). Mind the User! Measures to More Accurately Evaluate the Practical Value of Active Learning Strategies. Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing, 996–1006. https://aclanthology.org/2023.ranlp-1.107/
In der Serie Meet-the-Team stellen wir jede Woche ein Mitglied der Forschungsgruppe vor, um einen Eindruck jenseits der wissenschaftlichen Arbeit zu vermitteln. Dazu hat uns unserer studentischer Mitarbeiter Philippe Sander ein paar Fragen gestellt.
Heute im Interview: Tobias. Als politischer Soziologie gilt sein Interesse insbesondere dem Einfluss von Beteiligungsmöglichkeiten auf Legitimitätseinstellungen und wie diese mit der substantiellen „Qualität“ von Beteiligungsbeiträgen zusammenhängen. Darüber hinaus leitet er die Nachwuchsgruppe. Mehr Infos zu Tobias‘ Forschung finden sich hier.
Foto: Tilman Schenk
Was hat dich dazu inspiriert, eine Karriere in deinem Forschungsbereich anzustreben, und wie hast du in deinem Fachbereich begonnen?
Ich glaube, für mich war schon immer von Bedeutung, wie Menschen ihre Geschicke bestimmen können und wie man dafür sorgt, dass Gesellschaften sich darauf einigen, wie sie zusammenleben wollen. Von daher hat mich bereits früh im Studium interessiert, was politische Beteiligung ist und welche Rolle sie für politische Entscheidungen spielt. Am Anfang meiner Forschung ging es dabei vor allen Dingen um den Einfluss des Internets. Viele Fragen waren damals noch offen. Eine davon war zum Beispiel, ob sich durch die digitalen Möglichkeiten mehr Leute beteiligen würden als früher, oder ob man mit Online-Partizipation überhaupt etwas bewirken kann. Mittlerweile sind die neuen Medien nicht mehr neu und ich verfolge darüber hinaus andere Fragen, aber dem Thema Beteiligung bin ich treu geblieben.
Kannst du dein aktuelles Forschungsprojekt beschreiben und was du damit erreichen möchtest? Was findest du daran persönlich am interessantesten?
In unserem aktuellen Forschungsprojekt ist die Grundfrage letztlich, wie in den Kommunen die Verkehrswende und die Anpassung and den Klimawandel gelingen können. Denn Mobilität ist ein wesentlicher Faktor für die Emissionen. Aus meiner Sicht ist das komplexe Thema Klimawandel und was wir dagegen tun können keine technische Frage, sondern eher eine soziale. Konkret: Wie schaffen wir es, die Dinge – von denen wir wissen, dass wir sie tun müssen – auch so zu tun, dass sie entsprechend ökologisch, sozial und ökonomisch nachhaltig sind und von der Bevölkerung akzeptiert werden.
Wie gehst du bei deiner Forschung vor? Welche Methoden, Theorien oder Frameworks verwendest du?
Also, ich denke das spannende ist, dass wir in der Forschungsgruppe mit der Soziologie, der Stadtplanung und der Informatik zusammen sehr interdisziplinär arbeiten, und jede Disziplin hat ihre eigenen Theorien und Methoden. Im Bereich der Partizipationsforschung geht es zum einen um die ganz grundsätzliche Frage, welche Funktion die Beteiligung von Bürger*innen über Wahlen hinaus eigentlich hat. Da geben partizipative Demokratietheorien natürlich andere Antworten als liberale oder gar elitäre Demokratieverständnisse. Dann beschäftigen wir uns viel mit der Frage, wer sich überhaupt beteiligt und warum, oder eben auch nicht. In meiner Forschung orientieren wir uns da vor allem am Civic Voluntarism Model. Ansonsten interessiert mich vor allem, inwieweit die Beteiligung zu mehr Akzeptanz von Entscheidungen führt bzw. auch von den für die Entscheidung Verantwortlichen. Da reden von Legitimität und arbeiten da viel mit Easton, Scharpf oder Norris.
Methodisch ist das Projekt auch ziemlich spannend, da wir sowohl quantitativ als auch qualitativ arbeiten und versuchen, beides zu verbinden. In meiner Forschung gehen wir vor allem quantitativ vor, mit standardisierten Befragungen und entsprechenden quantitativen Analyseverfahren.
Was sind einige der größten Herausforderungen, mit denen du in deiner Arbeit konfrontiert bist, und wie überwindest du sie?
Dass wir immer die Balance halten müssen zwischen der eigentlichen Forschung, dem Management der Forschung und der restlichen Selbstverwaltung. Außerdem entsteht eine ganze Reihe von Herausforderungen, wenn Wissenschaft und Praxis aufeinandertreffen, zum Beispiel zeitlich, weil wir oft von der Planung der Städte abhängig sind, mit denen wir zusammenarbeiten. Im Projekt selbst ist es besonders, weil wir mit den verschiedenen Disziplinen arbeiten. Da muss man eine gemeinsame Sprache finden. Das ist nicht immer einfach.
Wie bleibst du auf dem neuesten Stand der Trends und Entwicklungen in deinem Fachgebiet?
Für uns in der Wissenschaft ist das zum einen der direkte Austausch mit den Kollegen*innen, also auf Konferenzen. Was ich ansonsten mache, ist, dass ich mir regelmäßig die neusten Artikel aus Zeitschriften schicken lasse, die ich generell lese und die relevant und einschlägig für mein Thema sind. Ich finde das eine ganz gute Methode, um nebenbei einen Einblick in aktuelle Themen, Methoden und Debatten zu erhalten, die mich interessieren.
Wie arbeitest du mit anderen Forscher*innen oder Expert*innen in deinem Bereich zusammen, um deine Projekte zu verbessern?
Ich halte es für wichtig, dass wir regelmäßig Feedback einholen, wie beispielsweise bei Kolloquien für Dissertationen oder in Workshops, die wir organisieren. Dabei erhalten wir dann auch Rückmeldungen von Personen außerhalb unseres Projektes. Zusätzlich haben wir für unser Projekt einen wissenschaftlichen Beirat, der uns wertvolle Tipps gibt. Meiner Meinung nach ist es vor allem der konstante Austausch mit anderen, der wichtig ist. Dies kann informell im universitären Umfeld geschehen, indem man sich auf dem Flur trifft und über Themen spricht, oder auch formell bei Konferenzen.
Welchen Einfluss hoffst du, dass deine Forschung auf die Gesellschaft oder das Feld haben wird?
Ich persönlich sehe den Klimawandel als die größte Herausforderung für die Menschheit an. Aus meiner Perspektive ist der weniger ein technisches Problem, sondern vielmehr ein soziales Problem, welches gelöst werden müsste. Wir haben zum großen Teil die Technologie dazu, aber scheitern daran, uns auf die notwendigen Maßnahmen wie beispielsweise ein Tempolimit zu einigen. Im Idealfall trägt unsere Forschung dazu bei, dass wir ein paar Aspekte herausarbeiten, bei denen man davon ausgeht, dass sie dabei helfen könnten. Aber vielleicht findet man auch Situationen, für die sich herausstellt, dass Bürger*innenbeteiligung nicht das richtige ist und andere Formate oder Mittel gefunden werden müssen. Die große Frage ist, wie die Transformation zu mehr Nachhaltigkeit gelingt, und an der versuchen wir, ein ganz kleines Stück mitzuarbeiten.
Kannst du uns von interessanten oder bedeutsamen Erfahrungen berichten, die du während deiner Forschung gemacht hast?
Das, was uns auszeichnet und was es besonders macht, ist die Zusammenarbeit mit der Praxis. Und da ist es eben immer wieder spannend, aus seinen akademischen Debatten herauszugehen und sich mit der Realität konfrontieren zu lassen. Da werden auch nochmal neue Akzente gesetzt. Wie gesagt, dass ist nicht immer einfach, aber das ist das was ich sehr schätze.
Vielleicht ein bisschen allgemeiner, aber was ich auch eine wichtige Erfahrung finde: Zu lernen, wie schön das ist, wenn andere Menschen, die man beim Beginn der wissenschaftlichen Karriere begleitet hat, gute Arbeit leisten und man das Gefühl hat, vielleicht doch einen gewissen Anteil daran zu haben, dass sie dann ihre Potentiale entfalten.
Welchen Rat hast du für Studenten und angehende Wissenschaftler, die gerade erst in ihre Karriere starten?
Die erste Frage, die man sich stellen muss ist: Was interessiert mich? Dabei ist die Balance zwischen Offenheit und Beharrlichkeit wichtig. Also nicht blind Trends zu folgen und Themen vorschnell fallen lassen, aber auch nicht beratungsresistent für die Vorschläge Anderer zu sein. Das zweite ist eher eine formale Sache. Die Wissenschaft hält unglaublich viel bereit. Das positive daran ist, man kann immer arbeiten, das negative ist, man wird auch immer arbeiten: diese Gedanken stellen sich ja nicht ab. Dessen muss man sich bewusst sein und für sich selbst entscheiden, ob das mit dem persönlichen Lebensplan zusammenpasst.
Schließlich, kannst du uns ein wenig über dich außerhalb deiner Arbeit erzählen? Welche Hobbys oder Interessen verfolgst du in deiner Freizeit, und wie ergänzen sie deine Forschung?
Das Thema Umweltschutz ist auch persönlich eines, dass mich begleitet. Zu fragen, was man persönlich tun kann, und wie man vielleicht auch andere davon überzeugt, ein bisschen mehr zu tun, als sie es jetzt tun. Damit gibt es mittlerweile eine schöne Verbindung zwischen dem was mir persönlich wichtig ist und was ich in meiner Forschung machen kann. Und so soll es ja auch sein. Ansonsten habe ich Familie und kann daher selten über Langeweile klagen.
Im Rahmen ihrer Masterarbeit im MA Sozialwissenschaften an der Heinrich-Heine-Universität Düsseldorf hat sich Maria Antonia Dausner mit den Herausforderungen von Schüler*innenpartizipation während der Corona-Pandemie beschäftigt, und dabei ausgewählte Grundschulen in NRW in den Blick genommen.
Zusammenfassung
Partizipation von Schüler:innen ist sowohl rechtlich in der UN-Kinderrechtekonvention verankert als auch aus demokratiepädagogischen und entwicklungspsychologischen Gründen von Bedeutung. In der Schule gibt es jedoch vielfältige Herausforderungen und Risiken, die diese im Alltag erschweren und dazu führen, dass Schüler:innenpartizipation oft nicht umfänglich gewährleistet wird. Während der Covid-19 Pandemie und den damit verbundene Schulschließungen wurde der Schulalltag unterbrochen und kollektive Lernprozesse konnten nicht stattfinden. Mit Bezug auf den komplexen Charakter von Schüler:innenpartizipation stellt sich daher die Frage, welche Folge die Herausforderungen im Rahmen der Schulschließungen und dem Online-Unterricht für Schüler:innenpartizipation haben. Es ist davon auszugehen, dass Schüler:innenpartizipation nicht in demselben Umfang weitergeführt wurde. Daher ist insbesondere von Interesse, welche Beispiele guter Schüler:innenpartizipation es gibt und wie diese aussehen können. Dazu wird folgende konkrete Forschungsfrage gestellt: Wie konnte gute Schüler:innenpartizipation während den Covid-19 bedingten Schulschließungen aussehen?
Um diese Frage zu beantworten, wurden qualitative leitfadengestützte Interviews an drei Grundschulen in Nordrhein-Westfalen durchgeführt. Diese Schulen wurden ausgewählt, da aufgrund ihrer Teilnahme am Landesprogramm-Kinderrechteschulen davon auszugehen ist, dass Schüler:innenpartizipation ein großer Stellenwert beigemessen wird. Es wurden insgesamt sechs Interviews mit der Schulleitung und Lehrkräften sowie Schüler:innen geführt, die nach dem Vorgehen der qualitativen Inhaltsanalyse von Mayring ausgewertet werden.
Anhand verschiedener Dimensionen von Partizipation zeigte sich, dass weniger Partizipationsformate weitergeführt wurden, Partizipation weniger intensiv war und Schüler:innen bei weniger Themen mitbestimmen konnten. Bei der Frage, was rückblickend hätte anders gemacht werden können, wurde gesagt, dass es kaum Verbesserungsvorschläge gibt und nichts anders gemacht worden wäre. Daran wird die Diskrepanz zwischen theoretischer Relevanz und praktischer Umsetzung deutlich und stellt insbesondere die Bedeutung von Schüler:innenpartizipation in Frage. Zudem zeigte sich, dass Schüler:innenpartizipation abhängig von dem Willen der Erwachsenen ist, diese zu ermöglichen und umfänglich umzusetzen. Eine konkrete Möglichkeit, Schüler:innenpartizipation weiterzuführen, stellte einen Wechsel in den digitalen Raum und das Nutzen von Lernplattformen sowie Videokonferenzen dar. Hier eröffnete sich ein neues Potential für Schüler:innenpartizipation, welches es zukünftig auszuschöpfen gilt. Trotz der Herausforderungen wurden teilweise auch in informellen Formaten Partizipationsmöglichkeiten für Schüler:innen geschaffen. Diese ermöglichten Raum für Austausch und Zusammenkommen, was vor dem veränderten (Schul-)Alltag der Schüler:innen von besonderer Bedeutung ist.
Publikation
Dausner, Maria Antonia (2022): Möglichkeiten von Schüler:innenpartizipation während den Covid-19 bedingten Schulschließungen – eine Analyse am Beispiel von Grundschulen in Nordrhein-Westfalen. Arbeit zur Erlangung des M.A. Sozialwissenschaften am Institut für Sozialwissenschaften der Heinrich-Heine-Universität Düsseldorf. (Download)
In diesem Artikel in der Zeitschrift Digital Government: Research and Practice geben Julia Romberg und Tobias Escher einen Überblick über automatisierte Techniken die bereits zur Unterstützung der Auswertung von Beiträgen in Beteiligungsprozessen verwendet wurden. Auf Basis einer systematischen Literaturstudie bewerten sie die Leistungsfähigkeit der bisher eingesetzten Verfahren und zeigen weiteren Forschungsbedarf auf.
Zusammenfassung
Öffentliche Institutionen, die Bürger*innen im Rahmen politischer Entscheidungsprozesse konsultieren, stehen vor der Herausforderung, die Beiträge der Bürger*innen auszuwerten. Unter demokratischen Aspekten ist diese Auswertung von wesentlicher Bedeutung, benötigt gleichzeitig aber umfangreiche personelle Ressourcen. Eine bislang noch zu wenig erforschte Lösung für dieses Problem bietet die Nutzung von künstlicher Intelligenz, wie beispielsweise computer-unterstützter Textanalyse. Wir identifizieren drei generische Aufgaben im Auswertungsprozess, die von der automatisierten Verarbeitung natürlicher Sprache (NLP) profitieren könnten. Auf Basis einer systematischen Literaturrecherche in zwei Datenbanken zu Computerlinguistik und Digital Government geben wir einen detaillierten Überblick über die existierenden Ansätze und deren Leistungsfähigkeit. Auch wenn teilweise vielversprechende Ansätze existieren, beispielsweise um Beiträge thematisch zu gruppieren oder zur Erkennung von Argumenten und Meinungen, so zeigen wir, dass noch bedeutende Herausforderungen bestehen, bevor diese in der Praxis zuverlässig zur Unterstützung eingesetzt werden können. Zu diesen Herausforderungen zählt die Qualität der Ergebnisse, die Anwendbarkeit auf nicht-englischsprachige Korpora und die Bereitstellung von Software, die diese Algorithmen auch Praktikter*innen zugänglich macht. Wir diskutieren verschiedene Ansätze zur weiteren Forschung, die zu solchen praxistauglichen Anwendungen führen könnten. Die vielversprechendsten Ansätze integrieren die Expertise menschlicher Analyst*innen, zum Beispiel durch Ansätze des Active Learning oder interaktiver Topic Models.
Ergebnisse
Es gibt eine Reihe von Aufgaben im Auswertungsprozess, die durch die automatisierte Verarbeitung natürlicher Sprache (NLP) unterstützt werden könnten. Dazu gehören i) die Erkennung von Duplikaten, ii) die thematische Gruppierung von Beiträgen, und iii) die detaillierte Analyse einzelner Beiträge. Der Großteil der Literatur in dieser Literaturstudie konzentriert sich auf die automatisierte Erkennung und Analyse von Argumenten, einen Aspekt der detaillierten Analyse einzelner Beiträge.
Wir stellen eine umfangreiche Zusammenfassung der genutzten Datensätze und der verwendeten Algorithmen vor, und bewerten deren Leistungsfähigkeit. Trotz der ermutigenden Ergebnisse wurde die deutlichen Entwicklungssprünge, in den letzten Jahren im NLP-Bereich erfolgt sind, bislang kaum für diesen Anwendungsfall genutzt.
Eine besondere auffällige Lücke besteht in der mangelnden Verfügbarkeit von Anwendungen, die Praktiker*innen die einfache Nutzung von NLP-basierten Verfahren für die Auswertung ihrer Daten erlauben würden.
Der Aufwand zur Erstellung von annotierten Daten, die zum Training von Modellen des maschinellen Lernens notwendig sind, kann dazu führen, dass sich die erhofften Effizienzvorteile einer automatisierten Auswertung nicht einstellen.
Wir empfehlen verschiedene vielversprechendsten Ansätze zur weiteren Forschung. Viele davon integrieren die Expertise menschlicher Analyst*innen, zum Beispiel durch Ansätze des Active Learning oder interaktiver Topic Models.
Publikation
Romberg, Julia; Escher, Tobias (2023). Making Sense of Citizens’ Input through Artificial Intelligence: A Review of Methods for Computational Text Analysis to Support the Evaluation of Contributions in Public Participation. In: Digital Government: Research and Practice 5(1): 1-30. DOI: 10.1145/3603254.
Soziale Ungleichheiten in der digitalen Beteiligung beruhen v. a. auf dem Second-Level Digital Divide, d.h. in Unterschieden in den medien- und inhaltsbezogenen Kompetenzen, die für die selbstständige und konstruktive Nutzung des Internets zur politischen Beteiligung notwendig sind.
Das Wissen zu Effektivität von Aktivierungsfaktoren ist nach wie vor oft lückenhaft und anekdotisch, dadurch sind Kosten und Nutzen einzelner Maßnahmen für die Initiator*innen häufig nur schwer abzuschätzen.
Zur (zielgruppengerechten) Mobilisierung eignet sich nachweislich die persönliche Einladung, aber auch die etablierten Massenmedien spielen nach wie vor eine wichtige Rolle.
Breite und inklusive Beteiligung erfordert die Kombination unterschiedlicher digitaler und analoger Partizipationsformate.
Beteiligungsformate auf nationale Ebene stehen aufgrund der Komplexität der Themen und der Größe der Zielgruppe vor besonderen Herausforderungen und erfordern daher kaskadierte Verfahren (Verzahnung von Beteiligung auf unterschiedlichen politischen Ebenen) sowie noch neu zu schaffende Institutionen.
Publikation
Lütters, Stefanie; Escher, Tobias; Soßdorf, Anna; Gerl, Katharina; Haas, Claudia; Bosch, Claudia (2024): Möglichkeiten und Grenzen digitaler Beteiligungsinstrumente für die Beteiligung der Öffentlichkeit im Standortauswahlverfahren (DigiBeSt). Hg. v. Düsseldorfer Institut für Internet und Demokratie und nexus Institut. Bundesamt für die Sicherheit der nuklearen Entsorgung (BASE). Berlin (BASE-RESFOR 026/24). Online verfügbar unter https://www.base.bund.de/DE/themen/fa/sozio/projekte-ende/projekte-ende.html .
Als Teilnehmende an einem Workshop des Center for Advanced Internet Studies (CAIS) in Bochum haben Julia Romberg und Tobias Escher die Ergebnisse aus der CIMT Forschung zur KI-unterstützten Auswertung von Beteiligungsbeiträgen vorgestellt und mit den anwesenden Expert*innen aus Forschung & Beteiligungspraxis über weitere Möglichkeiten diskutiert, um Künstliche Intelligenz für die Unterstützung von Öffentlichkeitsbeteiligung einzusetzen. Deutlich wurde dabei, dass die Praktiker*innen Potentiale nicht nur bei der Auswertung (Output), sondern auch bei der Aktivierung von Teilnehmenden (Input) sowie bei der Unterstützung der Interaktionen (Throughput) bei Beteiligungsverfahren sehen. Gleichwohl stehen diesen Potentialen Herausforderungen und Risiken gegenüber, unter anderem bei der adäquaten technischen Umsetzung sowie der Sicherstellung von Datenschutz und Diskriminierungsfreiheit.
Der von Dr. Dennis Frieß und Anke Stoll organisierte Workshop fand vom 8. bis 10. Februar 2023 in Bochum statt. Weitere Informationen finden sich auf der Website des Düsseldorfer Instituts für Internet und Demokratie.
Am 30. November haben wir Vertreter*innen der mit uns kooperierenden Kommunen eingeladen, um uns mit diesen über die ersten Ergebnisse aus den umfangreichen Befragungen unserer Forschungsgruppe auszutauschen. Im Mittelpunkt stand dabei die Frage, wie die jeweiligen Beteiligungsverfahren von den Teilnehmenden eingeschätzt werden, und welche Aspekte zur Teilnahme motivieren, oder davon abhalten.
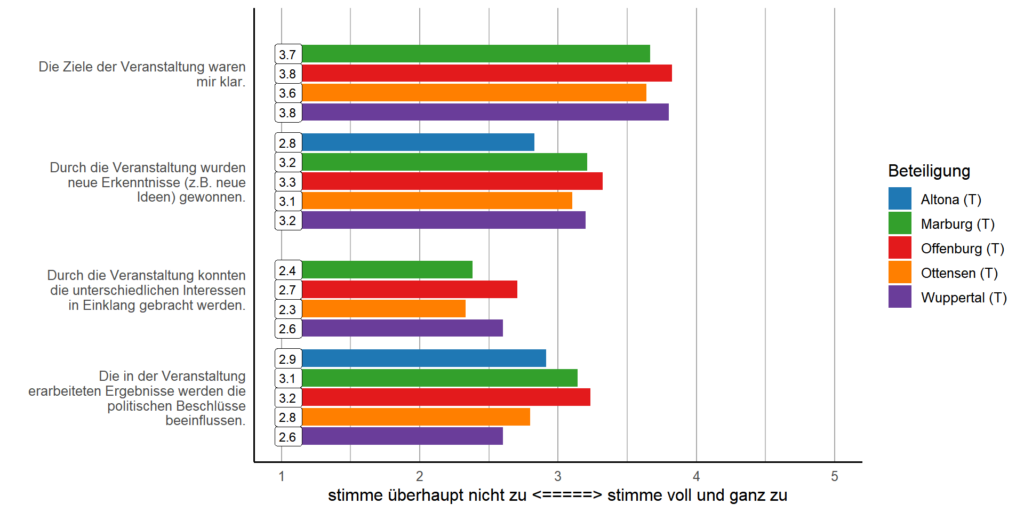
Trotz der Verschiedenheit der von uns untersuchten fünf Projekte (und der bislang z.T. noch geringen Zahl der Teilnehmenden) weisen die Einschätzungen der an solchen Prozessen partizipierenden Personen relativ große Übereinstimmungen auf. Insgesamt zeigen sich eher positive Bewertungen für die Beteiligungsverfahren im Hinblick auf den Diskussionsverlauf und die Transparenz. Gleichzeitig gibt es aber auch in allen Verfahren vergleichbare Herausforderungen. So wird z.B. die Repräsentation der eigenen Interessen als relativ gut bewertet, es werden aber Lücken in der Repräsentation anderer Meinungen wahrgenommen. Auch gelingt nicht immer ein Ausgleich der Interessen. Darüber hinaus sind die Teilnehmenden eher skeptisch, was die tatsächlichen Wirkung der Beteiligungsergebnisse auf den politischen Prozess angeht, wenn sie diese auch nicht ausschließen.
Einschätzung des von den Teilnehmenden besuchten Beteiligungsformats. N=286 (Altona: 61, Marburg: 22, Offenburg: 40, Ottensen: 158, Wuppertal: 5)
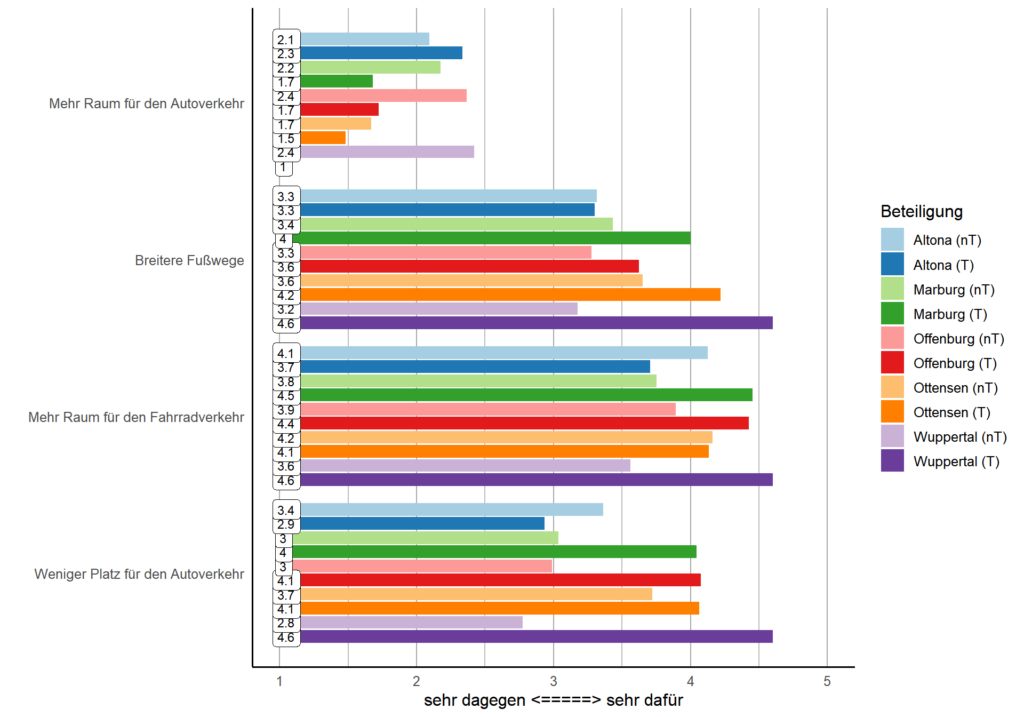
Interessante Unterschiede zeigen sich auch zwischen Teilnehmenden und Nicht-Teilnehmenden. Beispielhaft zeigt die untenstehende Auswertung die Anworten auf die Frage danach, wie der Verkehr in der jeweiligen Kommune in fünf Jahren aussehen sollte. In der Regel befürworten Personen, die am Beteiligungsverfahren teilgenommen haben (T) grundsätzlich eher eine Umgestaltung zur Förderung von Fahrrad- und Fußverkehr als die Personen, die sich nicht an diesen Verfahren beteiligt haben (nT). So finden sich also unter den Teilnehmenden eher Befürworter*innen der Verkehrswende. Allerdings zeigen sich auch hier durchaus Unterschiede zwischen den Verfahren, die darauf hindeuten, dass die Motive sich einzubringen durchaus sehr verschieden ausfallen können – ein Aspekt, den wir in den zukünftigen Analysen weiter verfolgen werden.
Frage: Wie soll der Verkehr in der jeweiligen Kommune in fünf Jahren aussehen? Dargestellt nach teilgenommen (T) oder nicht teilgenommen (nT) am Partizipationsverfahren N=1.587 (Altona: 432, Marburg: 417, Offenburg: 254, Ottensen: 342, Wuppertal: 142)
Der Praxisworkshop hatte das Ziel, diese ersten Befunde gemeinsam zu reflektieren, gerade auch im Vergleich des jeweils „eigenen“ Verfahrens mit den Ergebnissen aus den anderen untersuchten Kommunen. Dieser Austausch hat uns wichtige Hinweise auf mögliche Zusammenhänge geliefert und verdeutlicht, wo weiterer Klärungsbedarf besteht.
Die dargestellten Beispiele sind ein erster Einblick in die große Fülle an Daten, die mit Hilfe der Befragungen gesammelt wurden und die im Jahr 2023 noch erweitert werden wird (siehe Hintergrund unten). Der gemeinsame Austausch mit den kommunalen Partner*innen hatte daher auch den Zweck, genauer zu klären, welche Informationen für die kommunale Beteiligungspraxis relevant sind, und in welchen Formaten die gemeinsamen Diskussionen am sinnvollsten fortgeführt werden können.
Wir bedanken uns recht herzlich bei unseren Partner*innen für Ihre Zeit und Ihre Ideen!
Zum Hintergrund
Im Rahmen unserer Forschung interessieren wir uns insbesondere dafür, welche Rolle Bürger*innenbeteiligung beim Gelingen der Verkehrswende spielen kann. Dafür untersuchen wir unter anderem fünf verschiedene Beteiligungsverfahren:
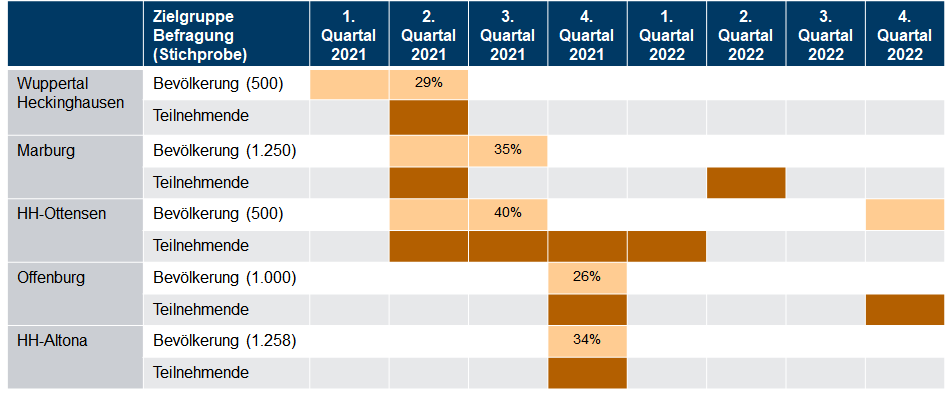
Für jedes Projekt wurde von uns ein umfangreiches Programm an Befragungen durchgeführt. Dafür haben wir zum einen eine Zufallsauswahl aus der gemeldeten Bevölkerung mit einem Fragebogen angeschrieben. Zum anderen wurden von uns im Rahmen der verschiedenen Beteiligungsformate Teilnehmer*innen befragt. Die folgende Tabelle vermittelt einen Überblick über die Befragungszeiträume einschließlich der Ausschöpfungsquoten der von uns durchgeführten Bevölkerungsbefragungen. Insgesamt wurden bislang rund 1.600 Personen befragt, von denen rund 300 an einem der untersuchten Beteiligungsverfahren teilgenommen haben.
Übersicht über durchgeführte Befragungen von Bevölkerung und Teilnehmenden (Prozentwerte geben Rücklaufquoten der Bevölkerungsbefragung wieder)
Die Forschungsgruppe CIMT (Citizen Involvement in Mobility Transitions) am Institut für Sozialwissenschaften der Heinrich-Heine-Universität Düsseldorf erforscht die Potentiale und Probleme von Bürger*innenbeteiligung an der Verkehrswende in deutschen Kommunen.
Für unser Team suchen wir zum 1. Februar 2023 bzw. zum nächstmöglichen Zeitpunkt eine
Studentische Hilfskraft (SHK) bzw. Wissenschaftliche Hilfskraft mit Bachelorabschluss (WHB)
Ausführliche Informationen finden Sie in unserer Ausschreibung. Bewerbungsfrist ist der 5. Dezember 2022.
Im Rahmen seiner Abschlussarbeit im Masterstudiengang Sozialwissen-schaften bei unserer Forschungsgruppe untersucht Herr Jan Krebs, wie nachhaltig die Mobilität von Zuschauerinnen und Zuschauern bei Bundesligaspielen ist. Konkret geht es darum herauszufinden, mit welchen Verkehrsmitteln die Fans zum Stadion kommen und welche Rolle dabei verschiedene Faktoren wie z. B. die Lage des Stadions, die Terminansetzung oder die Größe des Vereins spielen.
Dafür bitten wir aktuell alle Vereine der 1. Bundesliga, 2. Bundesliga und 3. Liga der Saison 2018/2019 um Mithilfe! Wenn Sie für einen der Vereine arbeiten, so möchte ich Sie herzlich um Ihre Mitarbeit bitten. Für jede Liga haben wir einen kurzen Fragebogen vorbereitet. Die Beantwortung sollte nur wenig Zeit in Anspruch nehmen. Wenn Sie keine konkreten Zahlen zur Beantwortung der Fragen im Fragebogen vorliegen haben, nehmen Sie gerne eine grobe Schätzung vor.
Wir möchten Sie bitten, die Fragen bis zum 22.04.2022 zu beantworten.Sie können den Fragebogen bequem am Computer ausfüllen und per E-Mail als PDF an Herrn Krebs schicken (Jan.Krebs@uni-duesseldorf.de).
Die neu gewonnen Daten sollen aufbereitet und wenn möglich, in einer wissenschaftlichen Publikation veröffentlicht werden, die darstellt wie Fuß-ballfans in Deutschland zum Stadion gelangen und wie nachhaltig deren Mobilität ist. Mit der Rücksendung des Fragebogens willigen Sie ein, dass die Daten für eine solche wissenschaftliche Publikation genutzt werden könnten.
Als Ansprechpartner für alle Ihre Fragen und Anregungen steht Ihnen Her Krebs unter Jan.Krebs@uni-duesseldorf.de zur Verfügung.
Für Ihre Teilnahme möchten ich mich im Voraus recht herzlich bedanken.