

Am vergangenen Freitag haben wir im Rahmen unseres 2. Praxisworkshops erste Ergebnisse zu unseren aktuellen Arbeiten zur automatisierten Auswertung von Beteiligungsbeiträgen vorgestellt. Insgesamt hatten wir 12 Teilnehmende, die in verschiedenen Rollen (Stadtplanung, Bürger*innenbeteiligung, Dienstleistung als Planende oder für Partizipation) mit der Auswertung von Beteiligungsbeiträgen Erfahrung haben.
Zu Beginn haben wir einen Ansatz vorgestellt, um einzelne Sätze in Beteiligungsbeiträgen als Vorschlag oder Zustandsbeschreibung (beziehungsweise beides oder nichts davon) zu klassifizieren. Das funktioniert in der Praxis auch automatisiert schon ziemlich gut, wie auch unserer Veröffentlichung in den Proceedings of the 8th Workshop on Argument Mining zu entnehmen ist.

Die Expertinnen und Experten konnten die Zuordnung in der Regel nachvollziehen, allerdings trifft es nur teilweise den Bedarf in der Beteiligungspraxis. So lassen sich aus Beschreibungen von Situationen vor Ort in der Regel auch häufig Vorschläge ableiten, bzw. aus Vorschlägen auch Einschätzungen der Situation vor Ort. Hier würde zunächst einmal vor allem eine Hervorhebung von solchen inhaltlich relevanten Sätzen (im Gegensatz zu allgemeinen Informationen im Beitrag) weiterhelfen, um eine Konzentration auf das Wesentliche zu ermöglichen. Auch wäre eine Unterscheidung in konkrete Vorschläge vs. allgemeine Forderungen oder Kritik an bestehenden Verhältnissen denkbar.
Eine von allem geteilte Feststellung war, dass der Auswertungsprozess immer das Lesen und Abwägen jedes einzelnen Beitrags durch die Verantwortlichen erfordert, nicht zuletzt um sicherzustellen, dass alle Beiträge gleich und fair behandelt werden. Während eine Vorsortierung oder eine Priorisierung wichtig ist, um die Bearbeitung durch die Verantwortlichen zu erleichtern, darf ein Algorithmus nie die finale Entscheidung über die aus einem Beitrag erwachsenden Konsequenzen haben. So ist auch sichergestellt, dass mögliche Fehlzuordnungen im Rahmen der automatisierten Klassifikation erkannt werden und die Entscheidungsprozesse transparent und nachvollziehbar bleiben.
Als Folge dieser grundlegenden Feststellung muss eine Automatisierung also vor allem darauf angelegt sein, die mit der Auswertung betrauten Personen in ihrer praktischen Arbeit zu unterstützen. Die Teilnehmenden des Workshops haben dabei vor allem die Rolle der thematischen Klassifikation von Beiträgen betont. Im Kontext der Verfahren im Fokus von CIMT, erfordert das hier vor allem die Zuordnung von Beiträgen zu verkehrsrelevanten Kategorien. Dabei gilt es zwischen generischen und prozess-spezifischen Kategorien zu unterscheiden. Einerseits gibt es eine ganze Reihe von Themen, die für alle Beteiligungsverfahren mit einem Mobilitätsfokus relevant sind. Dazu zählt die Erkennung von Verkehrsmitteln oder bestimmten verkehrsrelevanten Themen, z.B. Verkehrssicherheit oder Mobilitätsmanagement. Diese eignen sich insbesondere für Verfahren, die überwachtes Lernen anwenden, da die Erkennung vorab (auch auf anderen, vergleichbaren Datensätzen) trainiert werden kann. Im Gegensatz dazu haben viele der Beteiligungsverfahren aber auch immer spezielle Themen, die nicht vorab feststehen, sondern sich erst in der konkreten Beteiligung ergeben. Hier müsste dann gegebenenfalls auf nicht-überwachte Verfahren zurückgegriffen werden, die dann nach Abschluss eines Verfahrens die Menge der Beiträge nach Ähnlichkeiten (z.B. in der Wortverteilung) analysieren und clustern.
Zusätzliche inhaltliche Klassifikationen, die im Rahmen des Workshops vorgeschlagen wurden, umfassten:
- die Verortung von Vorschlägen (an der wir auch schon arbeiten)
- die Erkennung von Vorschlägen, die rasches Handeln erfordern (z.B. Hinweis auf akute Gefahrenstellen)
- Unterscheidung der Konkretheit von Vorschlägen (an der wir auch schon arbeiten)
Darüber hinaus wollten wir von den Workshopteilnehmenden wissen, in welcher Form eine solche Automatisierung dann auch den Auswertungsprozess sinnvoll unterstützen kann. Dazu haben wir einige mögliche Vorschläge für die Visualisierung der durch die Modelle vorgenommenen Klassifikationen gezeigt.
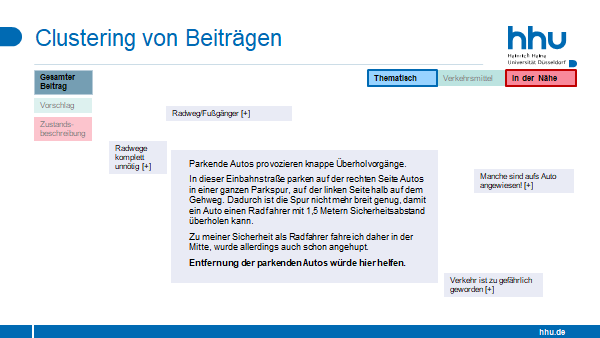
Hier war eine deutliche Präferenz für die Möglichkeit, gleichzeitige mehrere Themenschwerpunkte auswählen und visualisieren zu können (Anzeige von Schnittmengen). Um die auf Natural Language Processing basierenden Modelle in der Praxis auch anwendbar zu machen, bedarf es darüber hinaus einer geeigneten Softwarelösung, für die noch weitere Anregungen gemacht wurden:
- die Visualisierung der klassifizierten Beiträge, z.B. eine Übersicht über alle Beiträge einer Kategorie
- Möglichkeit der manuellen Nachkodierung von Beiträgen zulassen
- Ausgabe von Überblickstatistiken über alle Beiträge eines Verfahrens (z.B. Anzahl der Vorschläge in einer bestimmten Kategorie)
- Angabe eines Zuverlässigkeitswerts als Indikator dafür, wie „sicher“ sich der Algorithmus bei der Zuordnung ist
- weitergehende Informationen zu Beiträgen erfassbar machen, z.B.
- gelesen/ungelesen
- Bearbeitungsstatus
- Verantwortlichkeiten
Wir bedanken uns bei allen Teilnehmenden für die Zeit und den wichtigen Input. Insgesamt konnten wir damit wertvolle Erkenntnisse für die weitere Entwicklung von Analysewerkzeugen gewinnen. Einige davon befinden sich aktuell bereits ohnehin in der Entwicklung (z.B. die Erkennung von Verortungen oder die thematische Kodierung). Wir sind zuversichtlich, dazu bald weitere Ergebnisse zu präsentieren und damit einen weiteren Schritt zu machen, um die Verantwortlichen in der Beteiligungspraxis gezielt bei der Auswertung zu unterstützen.
Ein Kommentar zu „2. Praxisworkshop zur automatisierten Auswertung von Beteiligungsbeiträgen“
Die Kommentare sind geschlossen.