Am 31. Oktober, 07. November und 11. Dezember haben Praxisworkshops stattgefunden, bei denen wir Handlungsempfehlungen vorgestellt und mit den Teilnehmenden diskutiert haben. Teilgenommen haben Verwaltungsmitarbeiter*innen, die in den verschiedenen Kommunen mit denen wir kooperiert haben, für Bürger*innenbeteiligung verantwortlich sind und die an der Planung und Durchführung der Beteiligungsverfahren beteiligt waren, die wir in unserer Forschung untersucht haben.
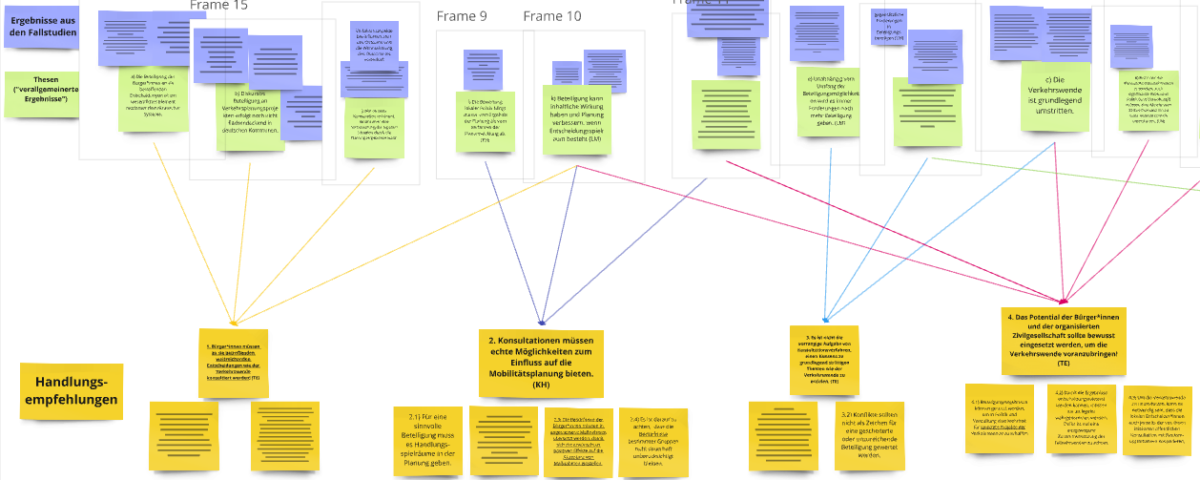
Im Zuge unserer Untersuchung verschiedener offener konsultativer Beteiligungsformate zum Thema urbaner Mobilitätsplanung, konnten wir verschiedene Erkenntnisse generieren, aus denen sich Thesen ableiten lassen. Diese Vielzahl an Thesen haben wir in einem weiteren Schritt zu sieben Handlungsempfehlungen verbunden, die bei der Umsetzung konsultativer Beteiligungsformate unterstützen sollen. Zu Beginn der Workshops haben wir den Weg von der Erkenntnis zur Handlungsempfehlung an einem Beispiel skizziert, bevor die Praktiker*innen selbst tätig wurden und in unserer Mindmap Kommentare hinterlassen konnten. Mit Hilfe digitaler Klebezettel haben sie ihre Meinungen, Ergänzungen, Kritikpunkte und Erfahrungen zu den einzelnen Handlungsempfehlungen angebracht. Im Anschluss daran gab es dann Diskussionen zu einzelnen Handlungsempfehlungen. Wichtige Punkte waren:
- Die Nützlichkeit der Handlungsempfehlungen in der Beteiligungspraxis als Tools zur Einordnung der eigenen Beteiligung
- Die Nützlichkeit der Handlungsempfehlungen in der Beteiligungspraxis als Begründungshilfe für die Wichtigkeit von Beteiligung
Die Expert*innen waren sich insgesamt einig, dass die Ergebnisse unserer Forschung sehr hilfreich sind, um gegenüber der Politik die Herausforderungen der Bürger*innenbeteiligung und die daraus folgenden Konsequenzen zu kommunizieren. Zusätzlich merkten viele der Praktiker*innen an, dass sie die Verknüpfung zu den Ergebnissen der Forschung übersichtlich und strukturiert fanden. Einige hatten den Eindruck, dass Beteiligungen, spezifischer Konsultationen in kommunalen Verwaltungen kritisch gesehen werden. Sie teilen die Einschätzung, dass unsere Ergebnisse einen Beitrag leisten können Verwaltungsmitarbeiter*innen zu schulen und ihnen die Nützlichkeit von Beteiligungsverfahren nahe zu bringen.
Größere Diskussionspunkte in den Workshops waren:
- die Konkretheit der Handlungsempfehlungen und das Einbinden von Beispielen in die Ergebnisdarstellung
- eine potentiell stärkere Betonung des Transparenzaspekts durch die Handlungsempfehlungen
- eine Anordnung der Handlungsempfehlungen in der zeitlichen Reihenfolge eine Partizipationsprozesses
Die Planer*innen merken an, dass die Handlungsempfehlungen konkretisiert werden könnten, um den Praxisbezug zu verdeutlichen und sie eher Anwendung finden zu lassen. In ihrer vorgestellten Form waren sie eher allgemein Gehalten und immer in strenger Relation zu den Ergebnissen der Forschung. Es wurde vorgeschlagen die Empfehlungen mit Beispielen aus konkreten Beteiligungsformaten zu unterfüttern. Beispielsweise könnten dafür unsere Forschungsgegenstände genannt werden, die unseren Erkenntnissen, den Thesen und damit auch den Handlungsempfehlungen zu Grunde liegen.
Obwohl Umformulierungen und Konkretisierungen vorgenommen wurden, sind Beispiele nicht direkt in den Empfehlungen zu finden. Dies wäre vor allem in Bezug auf die teils abstrakten und quantitativen Ergebnisse kompliziert gewesen. In Teilen bilden Beispiele aus den konkreten Partizipationsverfahren aber die Grundlage für das Erarbeiten der Handlungsempfehlungen und werden zum Teil zum Unterstreichen der Wichtigkeit genutzt.
Ein weiterer Aspekt, den die Expert*innen angebracht haben ist, dass sich in einem Planungsprozess zu verschiedenen Zeitpunkten unterschiedliche Aufgaben und Fragen stellen. Die sieben Handlungsempfehlungen beziehen sich teilweise auf die Planung, Umsetzung oder Auswertung der Verfahren. Dabei wurde vorgeschlagen spezifisch auf den Partizipationsprozess zu achten und die Handlungsempfehlungen entsprechend anzuordnen. Dies wurde umgesetzt.
Zum Abschluss der Workshops haben wir nach Anregungen für die Veröffentlichung der Ergebnisse gefragt. Dabei wurde betont wie wichtig eine gute Auffindbarkeit für die Planer*innen ist und empfohlen bereits bestehende Netzwerke zu nutzen, um die Ergebnisse möglichst weit streuen zu können.
Wir bedanken uns bei den Praktiker*innen für Ihre Zeit und den wichtigen Input – sowie in großen Teilen die jahrelange Kooperation. Es kamen viele wichtige Erkenntnisse und Anregungen zusammen, die uns bei der Arbeit an einer hilfreichen und praxisnahen Veröffentlichung der Handlungsempfehlungen helfen.